Vector Database Alternative: Graphs
12-03-2024

Given a large corpus of documents and a query, how do I select and rank the most relevant documents/passages to answer the query? That is the question Information Retrieval (IR) tries to answer. Through the years, many different approaches were born, each with pros and cons. In this article, we will explore some of these approaches and how Blar AI aims to leverage each of the pros while improving on the shortcomings. This article explains how gaining greater information context has allowed relevant improvements in Information Retrieval throughout the years.
Note: From now on, I refer to documents, but consider that it could also refer to a sentence, a passage paragraph, etc.
Key Word Search
If I gave you a text, imagine a white paper that you have never read Blar-SQL¹, and I asked you to answer a question based on that text, for example, What does the non-trusting interaction refer to? What approach would you take? One alternative is to read the whole text and answer the question. That is a valid approach, but it would take some time. A second approach would be to use Command+F for non-trusting interaction to read the few passages that match and answer the question. This approach is much quicker than reading the whole white paper.
Now, what if instead of a single white paper, you have hundreds or thousands of white papers? Suddenly, the Command+F approach is not practical. An alternative option to maintain the search capabilities is to create a library that keeps track of your documents. However, you would be required to index them first to search for a given query.

Image by maniacvector on Freepik
Now, the question becomes how exactly you index the documents to answer a query correctly. The answer is that it is required to create a lookup table. It works by taking all the unique words in a document or passage and creating a table where the key is that unique word and the value is the document where you found that word. Think of it as hitting Command+F for each word. If the word exists in some document, you add the document to the list of documents containing that word (e.g., non-trusting : [doc1, doc2]). That is the main idea behind inverted indexing. A small problem you may encounter is that common words (e.g., a, the, and, etc.) appear in every document. These words are stop words and usually need to be removed from the index.
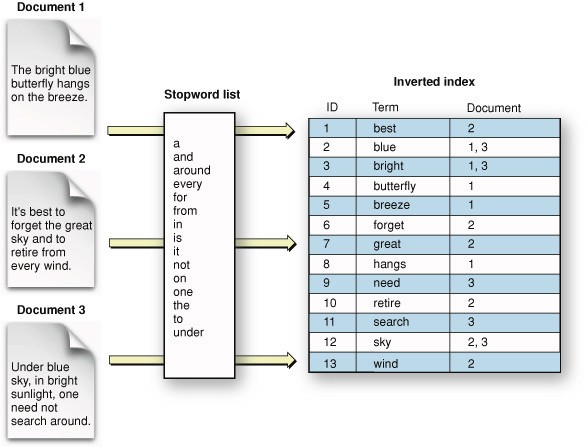
Image from: https://j.blaszyk.me/tech-blog/exploring-apache-lucene-index/
Now, if you need to answer what is a non-trusting interaction, instead of hitting Command+F in each document, you search for non-trusting in your index, which returns a list of relevant documents containing the request [doc1, doc3, doc4]. Next, you search for the word interaction and get another list of documents [doc2, doc4, doc5]. Finally, to determine relevance, we calculate a score based on how many times each document appears in these lists. For instance, documents 1, 2, 3, and 5 appear once, while document 4 appears in both results. Therefore, document 4 is likely more relevant to your query. This indexed system takes effort initially but saves time in the long run.
This approach has the advantage of being incredibly fast for lookup and can support billions of documents. The problem is that it is a very naive approach. What if the person who created the query asked for a synonym instead of the exact match? For example, someone asked: what does the distrustful approach refer to? In this case, none of the indexes would match, and there would not be a relevant document to answer the question. A second problem occurs when words have different meanings depending on the context. For example, what are the top-selling Apple hardware products? In this context, the question probably refers to Apple as the company, not the fruit. Using this approach, we have little to no context on the words used, the question, or the documents.
Semantic Search
Now, the problem becomes how a computer can tell that a word has a different meaning depending on the context. How can a computer tell that two words are synonyms? In other words, how can you teach language to a computer that only understands numbers? To answer that question embeddings were born, to convert words into vectors. With embeddings, the computer can tell that two words are similar if their vectors are similar (close together). You could do math operations between vectors, for example, you could take the vector for king, subtract the vector for men, add the vector for women, and would get the vector for queen.
The embedding generation requires an entire article by itself, but what is noteworthy to highlight is that advancements in machine learning played a crucial role in creating embeddings that follow the characteristics previously described. It means there are already available models trained with billions of words to receive natural language words and deliver embeddings as output.

Image from https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
Besides creating embedding for individual words, we can generate embeddings for longer sentences. It works by calculating the average of all the embeddings in a sentence to generate a new embedding². This way, we can solve the problem of synonyms as two similar words would have similar embeddings. We can also solve the context problem as the average of the sentence: Apple hardware products will more closely resemble Apple, the company, instead of apple, the fruit.
To create a semantic search, you first need to generate an embedding for each document by passing the document through a pre-trained model. Then, you create an embedding of your question. Finally, you compare your question embeddings with all your document embeddings³, and the one with the closer similarity is the most relevant to answer your query.
This approach solves both of our previous problems of word context and synonyms. But this approach has its problems by itself. For example, how much text is appropriate per embedding? If you embed a whole white paper in a single vector, most of the information would be lost, and your vector comparison would output useless information. On the other hand, embedding each sentence is resource-intensive and may not provide sufficient context to answer queries. So the question is: what is the sweet spot? And the answer is yet to be determined. That is the chucking problem. It refers to splitting your document into the correct number of chunks to get the best results.
A second problem this approach has is when there are very similar documents with slight differences. For example, when answering a question based on a specific customer X insurance policy info, most insurance policies would look the same and contain almost the same information except for some key differences. With vector similarity, it is almost impossible to distinguish those distinctions.
A third problem is that I cannot ask questions regarding the complete structure of a document, for example, how many different policies customer X has. A semantic search might return relevant policy passages, but nothing guarantees that it would return all of them, let alone the policy count. A second example might be what is the first and most relevant symptom that patient X has. Again, the semantic search would return the symptoms, but it couldn't know which is the first and most relevant.
This approach introduced sentence and word context to the equation, but it is still missing broader context, like what is the context of this sentence? Where is the document located? What is the context of the asked question? Is it asked by someone who cares about finance, or is it asked by someone who cares more about medicine? This information is key to getting the correct results and to suggest the best documents to answer a question.
Blar Graph Search 0.1
So how can you solve these problems? Since embeddings are individual data points, they don’t contain information about their surroundings or context, just the information within the embedding itself. Here is where graphs come to save us. A graph is a collection of nodes connected via edges. It is a versatile structure that can represent all kinds of situations, from social networks to traffic.

A graph representation of a single document using Blar’s technology mounted on Neo4J
So, how can graphs help us? Graphs have the unique ability to connect data points. This way, we can model a whole file in a graph structure, allowing each embedding to gain context of its surroundings. Moreover, we can look at documents as a whole and not just as a scattered collection of embeddings. We could also create a connection between customers and documents, giving us the ability to identify relationships between all data points.
To search for information in a given graph, Blar leveraged semantic search but combined it with a graph structure, complementing each node with more information about its surroundings. To achieve this, we used GNNs or graph neural networks (a machine learning model that runs on graphs). GNNs have the ability of message-passing, this way, each node passes and receives some information from its neighboring nodes complementing each node's information.

Image from: https://www.aritrasen.com/graph-neural-network-message-passing-gcn-1-1/
This approach showed promising results, increasing the accuracy and relevance of retrieved nodes. It better answered questions like “Give me the customer’s X insurance policy” as the insurance policy node contained some information about the customer’s X node.
Although this approach showed promising results, we believe it’s not enough. Some of the limitations include scalability, which we plan to solve by leveraging previous technology to reduce search space and use Blar’s technology to improve upon this reduced space. This idea is called re-ranking. Secondly, instead of using semantic search to compare each node, we are working on a model capable of retrieving the correct path to a given query. In the case of a customer’s X insurance policy, the idea is to compare and retrieve the whole path connecting the relevant nodes instead of identifying the nodes as individuals. Finally, we are working on a novel and more general way of constructing the graph to correctly traverse the graph and gather the most relevant documents to a given query.
¹ Shameless self-promotion
² There are also more advanced techniques
³ There are smarter ways than comparing 1 by 1