How We Built a Tool to Turn Any Code Base into a Graph of Its Relationships
17-12-2024
Software development is a complex and intricate process. It involves multiple people, teams, and technologies, all working together to create a product. As the project grows, it becomes increasingly difficult to understand how different parts of the system interact with each other. Code bases often become interconnected webs of dependencies, hierarchies, and communication flows. Without a clear map, understanding the relationships between modules, functions, and files can be a daunting task. This lack of visibility can lead to longer debugging times, inefficient collaboration, and even the accidental introduction of bugs.
What if you could visualize your entire project as a graph? What if you could see how different parts of the system are connected, and how changes in one part of the codebase affect other parts? What if you could use this graph to navigate your code, understand its structure, and identify potential issues before they become problems? That is exactly what we set out to build.
I will share how we built this tool, the challenges we faced, decisions we made and lessons we learned along the way.
Breaking Down the Problem: Hierarchy and Reference
At the core of any project are two fundamental relationships: hierarchy and references.
Hierarchy refers to the structure, such as how files are organized into directories, how classes are nested within each other, and how functions are defined within classes.
References refers to how different parts interact with each other, such as function calls, variable assignments, and imports.
To accurately extract and represents these relationships, we decided to divide the problem into two main steps:
Step 1: Building the hierarchy with tree-sitter
With the help of tree-sitter, a parsing library that can generate abstract syntax trees (ASTs) for code in various programming languages, we were able to extract the hierarchical structure of the codebase.
By parsing the code and analyzing the AST, we could identify folders, files, classes, functions, and methods, and create a graph that represents their containment relationships.
Folders and files: provide the top-level structure of the project.
Definitions within files, such as classes, functions and methods: provide the internal structure of the project.
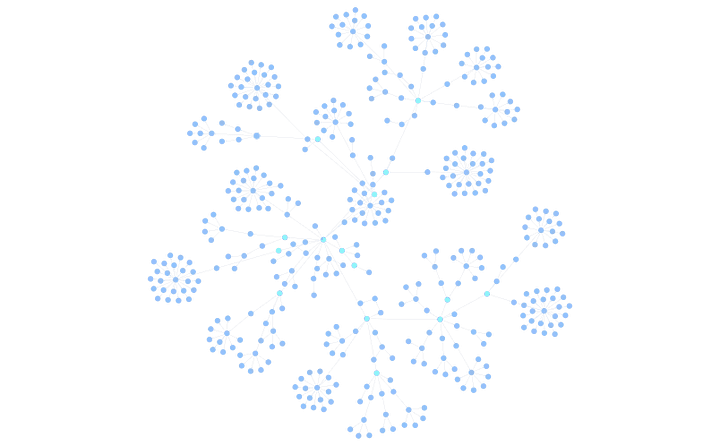
The result of this step is a graph that represents the hierarchical structure of the codebase, with nodes representing folders, files, classes, functions, and methods, and edges representing the containment relationships between them.
Here is an example of our own repo visualized as a graph after this step:
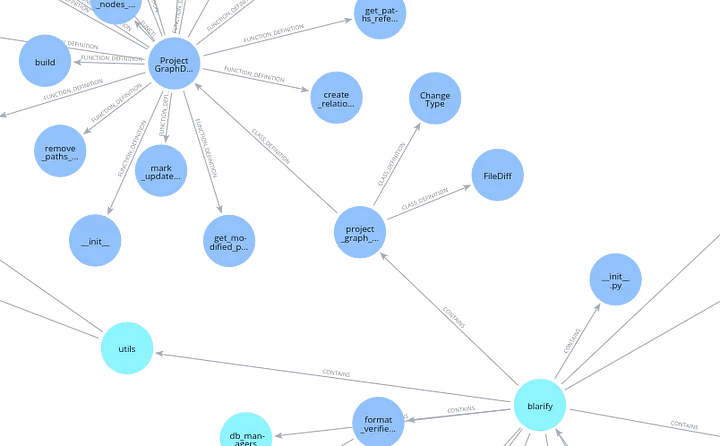
If we zoom in, we can see the internal structure of a file, with classes, functions, and methods:
Step 2: Finding references with the Language Server Protocol
The next step is to find references between different parts of the codebase. This involves analyzing the code to identify function calls, variable assignments, and imports, and creating edges in the graph to represent these relationships.
Luckily, we can leverage the Language Server Protocol (LSP) to perform this analysis.
The LSP is a protocol that allows IDEs and code editors to communicate with language servers, which provide language-specific analysis and tools.
By using the LSP, we can extract references without having to implement language-specific parsers and analyzers.
By querying the LSP for references to each node in the graph, we can create edges that represent the relationships between different parts of the code.
Even though the LSP provides a powerful way to extract references, it does not specify how is the reference being made. For example, it does not tell us if a reference is a function call, a variable assignment, or an import. To address this, we use tree-sitter to analyze the code and determine the type of reference.
Also, not all LSP implementations provide the exact same set of features
For each language, we define a set of node types that represent different kinds of references, such as function calls, variable assignments, and imports. We then go up the AST from the reference to find the nearest node that matches one of these types, and use it to determine the type of relationship.
The result of this step is a graph that represents the relationships between different parts of the project.
Here is an example of our own repo visualized as a graph after this step:
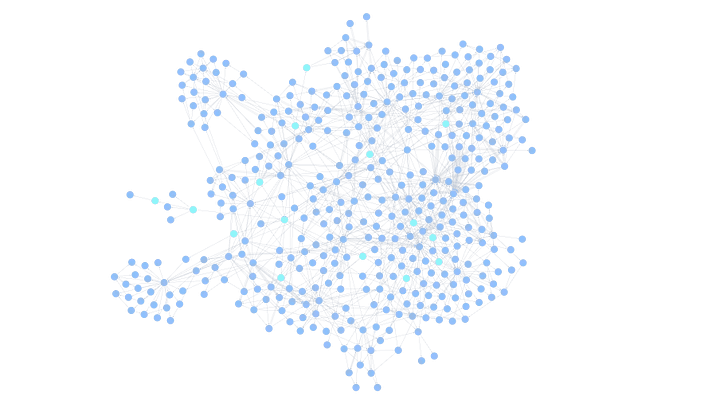
It is a little bit more messy, since it shows all the connections with different parts of the code, but it also provides a lot of insights into how different parts interact with each other.
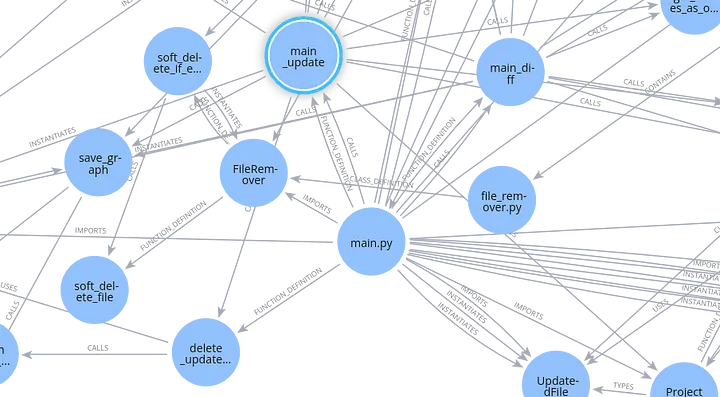
Here is a zoomed-in view of main.py:
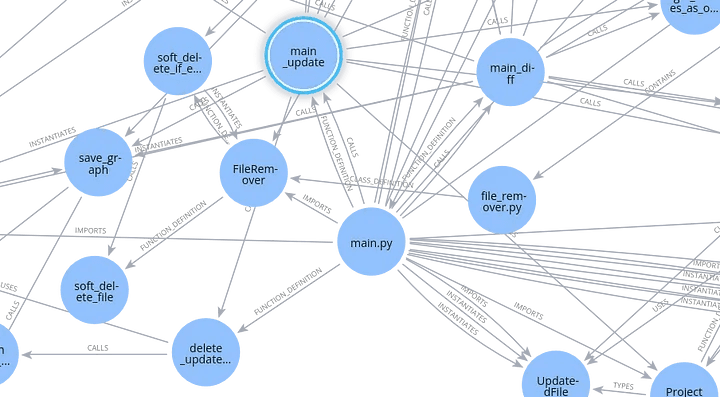
As you may expect, main.py file has a lot of references to other parts of the code.
Conclusions
Code bases are messy, complex, and constantly evolving. Understanding the relationships between different parts of it is crucial for effective collaboration, debugging, and maintenance. By visualizing the project relations as a graph, we can gain insights into its structure, identify potential issues, and navigate it more efficiently.
Turning a code bases into a graph is just the beginning of a larger journey. While visualizing the relationships and structure of a repository is powerful on its own, the real value lies in the tools and insights built on top of it. By analyzing and interpreting these graphs, we can unlock a deeper understanding of how systems work, identify bottlenecks, and make more informed decisions.
At Blar, we’re excited to continue pushing the boundaries of what’s possible. Our mission is to empower developers, teams, and organizations with tools that make complex projects more accessible, navigable, and insightful. Whether it’s streamlining workflows, enhancing collaboration, or integrating with AI-driven solutions, this journey is just getting started.